Playwright UI 自动化
文档 此篇内容只能带你入门,遇到问题多看文档才是正事儿。
你不可能记住所有的方法,知道流程和关键信息很重要!!!
pip install playwright
# 如果需要集成到 pytest 需要额外安装
pip install pytest-playwright
# 安装需要的浏览器
playwright install
## uv 操作如下
uv add playwright
uv run playwright install第一个脚本,你需要记住的是,在 selenium 中大多数场景可能需要 time.sleep(5) 等待元素或浏览器加载完成再去做事情。
而在 playwright 中你几乎不需要这么做,因为它具有自动等待的功能,如果一定要使用的话,可以 page.wait_for_timeout(5000)
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# 定义使用的浏览器
# headless 是否以无头模式运行(即浏览器没有打开)默认 True
# p.firefox.launch()
# p.webkit.launch()
browser = p.chromium.launch(headless=False)
# 打开新页面
page = brower.new_page()
# 去往这个地址
page.goto("https://playwright.dev/")
# 截图
page.screentshort(path="example.png")
# 关闭浏览器
brower.close()除此之外,playwright 提供两套 api 也可以异步的去调用。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("https://playwright.dev/")
await page.screenshot(path="example.png")
await browser.close()
asyncio.run(main())如果你觉得 with 语句比较麻烦,每次逻辑都要再增加缩进。可以调用 async_playwright().start() 来不使用 with 语句。
就像文件操作一样,此时再关闭时要调用 stop 关闭方法
sync_playwright
它的 start() 方法返回值用于创建浏览器、关闭浏览器、打开网页。
import playwright.async_api from sync_playwright
def main:
p = sync_playwright.start()
# 打开浏览器
brower = p.chromium.launch()
brower = p.firefox.launch()
brower = p.webkit.launch()
# 打开网页
page = browser.new_page()
page.goto('http://www.baidu.com')
# 关闭网页
page.close()
# 关闭浏览器驱动
p.stop()如果需要做 H5 的测试可以使用 context 模拟移动设备
from playwright.async_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
# 指定移动端设备
iphone_11 = p.devices["iPhone 11"]
# 创建移动设备的浏览器
context = browser.new_context(**iphone_11)
# 打开新的标签页
page = context.new_page()
page.goto('http://www.baidu.com')
context.close()Browser
| 方法、属性 | 作用 | 参数 | 返回值 |
|---|---|---|---|
close() | 关闭浏览器 | 无 | 无 |
new_context() | 创建一个新的浏览器上下文 | 无 | context |
new_page() | 创建一个新的标签页 | 无 | page |
browser_type | 获取浏览器的类型 | 无 | |
is_connected() | 是否已连接 | 无 | bool |
version | 返回浏览器版本 | 无 | str |
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
print(browser.browser_type) # chromium
print(browser.is_connected()) # True
print(browser.version) # 版本号
page = browser.new_page()
context = browser.new_context()
browser.close()Page
| 方法、属性 | 作用 | 参数 | 返回值 |
|---|---|---|---|
goto(url) | 跳转到指定的 url | url | Response |
screenshot(path) | 截图 | path | 无 |
title() | 获取当前页面的标题 | 无 | str |
url() | 获取当前页面的 url | 无 | str |
content() | 获取当前页面的 HTML 内容 | 无 | str |
viewport_size | 获取或设置视口大小宽、高 | dict | dict |
定位器
文档 用于定位页面元素,playwright 提供了多种定位方式。
| 方法 | 作用 |
|---|---|
page.get_by_role() | 通过显式和隐式可访问性属性进行定位。 |
page.get_by_text() | 通过文本内容定位。 |
page.get_by_label() | 通过 <label> 的文本定位到表单元素。 |
page.get_by_placeholder() | 通过占位符文本定位。元素的 placeholder 属性 |
page.get_by_alt_text() | 通过替代文本定位。通常是图片的 alt 属性 |
page.get_by_title() | 通过标题属性定位。通常是 <a> 或 <area> 元素的 title 属性 |
page.get_by_test_id() | 根据元素的自动以属性定位,通常 data-xxx |
page.locator() | 通过选择器定位。支持 CSS 选择器、XPath 选择器等 |
get_by_role 是一个标准化的方式,支持如下内容,跟原生标签有点对不上号...
['alert', 'alertdialog', 'application', 'article', 'banner', 'blockquote', 'button', 'caption', 'cell', 'checkbox', 'code', 'columnheader', 'combobox', 'complementary', 'contentinfo', 'definition', 'deletion', 'dialog', 'directory', 'document', 'emphasis', 'feed', 'figure', 'form', 'generic', 'grid', 'gridcell', 'group', 'heading', 'img', 'insertion', 'link', 'list', 'listbox', 'listitem', 'log', 'main', 'marquee', 'math', 'menu', 'menubar', 'menuitem', 'menuitemcheckbox', 'menuitemradio', 'meter', 'navigation', 'none', 'note', 'option', 'paragraph', 'presentation', 'progressbar', 'radio', 'radiogroup', 'region', 'row', 'rowgroup', 'rowheader', 'scrollbar', 'search', 'searchbox', 'separator', 'slider', 'spinbutton', 'status', 'strong', 'subscript', 'superscript', 'switch', 'tab', 'table', 'tablist', 'tabpanel', 'term', 'textbox', 'time', 'timer', 'toolbar', 'tooltip', 'tree', 'treegrid', 'treeitem']默认情况下,应该是打不开 debug 页面,无法判定这些选择器是否成功。可以安装 pytest 作为配合进入调试模式,此时就要遵循规范将方法名以 test_ 开头
uv add pytest-playwright pytestfrom playwright.sync_api import sync_playwright
def test_locator():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("http://127.0.0.1:5500/template/index.html")
# 根据图片的 alt 属性获取元素
image = page.get_by_alt_text('Google Logo')
print(image)
# 通过文本类型定位
text = page.get_by_text('Submit')
print(text)
# 通过 label 标签的文本定位到表单元素
name_input = page.get_by_label('Name:')
print(name_input)
# 通过占位符定位 元素的 placeholder 属性
placeholder_input = page.get_by_placeholder('Enter your name')
print(placeholder_input.all())
# 通过元素的 title 属性定位
title = page.get_by_title('Playwright Document Title')
print(title.inner_text())
# 通过可访问属性访问
list_item = page.get_by_role('listitem')
print(list_item.all_inner_texts())
if __name__ == '__main__':
test_locator()
# 输出结果如下
# selector='internal:attr=[alt="Google Logo"i]'>
# selector='internal:text="Submit"i'>
# selector='internal:label="Name:"i'>
# [
# selector='internal:attr=[placeholder="Enter your name"i] >> nth=0'>,
# selector='internal:attr=[placeholder="Enter your name"i] >> nth=1'>
# ]
# Playwright Document Title
# ['Item 1', 'Item 2']此时运行调试脚本 PWDBUG=1 uv run pytest -s xx.py 即可进入调试模式。如下
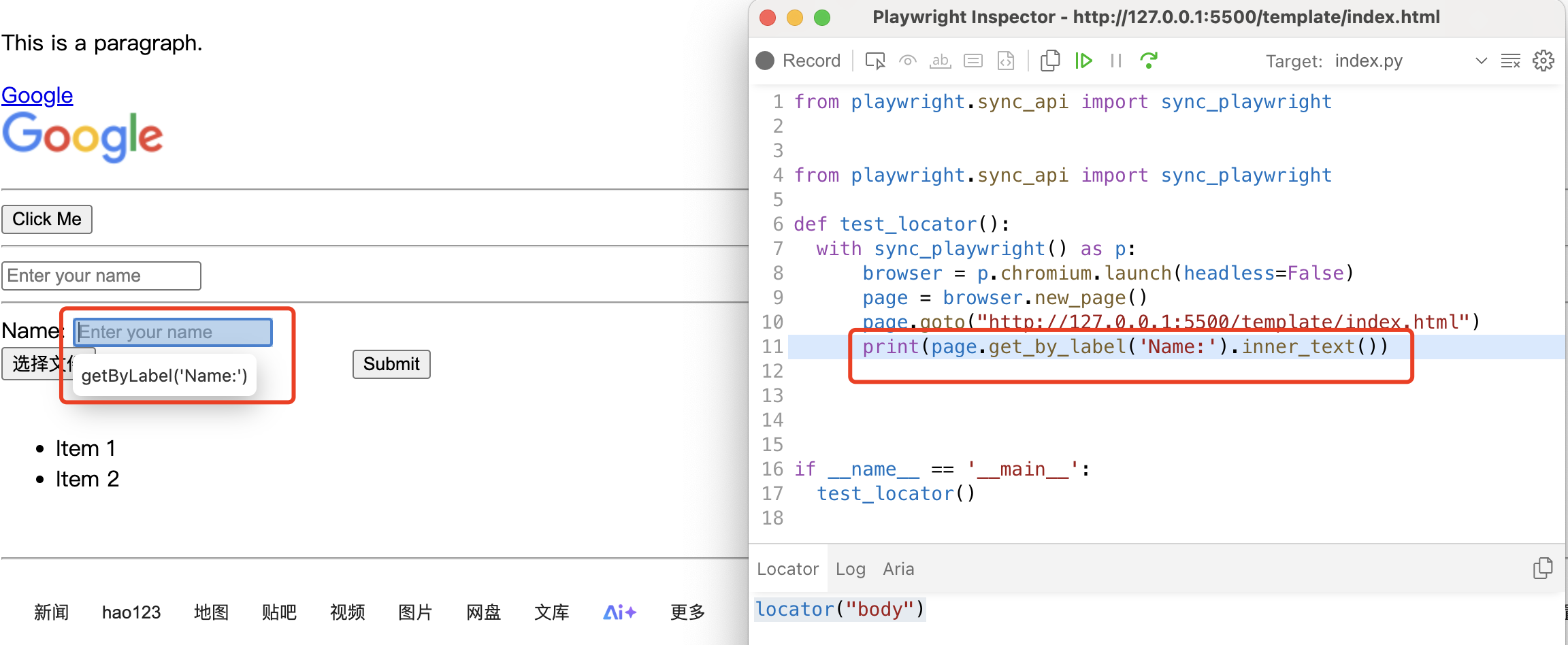
选择器的返回还是选择器,因此允许链式调用,这样对于一些复杂的元素定位会非常方便。
from playwright.sync_api import sync_playwright
def test_locator():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("http://127.0.0.1:5500/template/index.html")
# 链式调用
form_button = page.get_by_role('form').get_by_role('button')
print(form_button)
# css 选择器
css_form_input = page.locator('input[name="name"]')
print(css_form_input)
if __name__ == '__main__':
test_locator()元素句柄(元素操作)
文档,当元素被定位后,势必要做一些操作比如点击、输入文本等。
操作类
| 方法 | 作用 | 参数 |
|---|---|---|
click() | 点击元素 | button='left'/'right'/'middle'click_count=1delay=0 |
dblclick() | 双击元素 | button='left'/'right'/'middle'delay=0 |
check() | 选中复选框或单选按钮 | |
uncheck() | 取消选中复选框或单选按钮 | |
fill(value) | 填充输入框 | value |
focus() | 聚焦元素,输入框默认点击进去 | |
hover() | 鼠标悬停在元素上 | |
set_checked(value) | 设置复选框或单选按钮的选中状态 | value |
set_input_files(files) | 用于文件上传 | files |
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# ...
# 选中单选按钮
radio = page.locator('input[type="radio"]')
radio.set_checked(True)
# 选中复选框
checkbox = page.locator('input[type="checkbox"]')
checkbox.check()
# 输入框输入内容
input = page.locator('input[placeholder="Enter your name"]').all()
input[1].fill('Playwright')
# 点击提交按钮
submit = page.locator('.submit')
submit.click()获取内容类
| 方法 | 作用 | 参数 |
|---|---|---|
text_content() | 获取元素的文本内容 | |
inner_text() | 获取元素的内部文本内容 | |
inner_html() | 获取元素的内部 HTML 内容 | |
get_attribute(name) | 获取元素的属性值 | name |
input_value() | 获取input/textarea/select 的内容 |
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# ...
# 获取按钮的文本内容
print(page.locator('.submit').text_content())
# 获取 label 标签的文本内容
print(page.locator('label').inner_text())
# 获取 radio 的 name 属性
print(page.locator('input[type="radio"]').get_attribute('name'))
# 获取输入框的内容
print(page.locator('#name').input_value())辅助类
| 方法 | 作用 | 参数 |
|---|---|---|
scroll_into_view_if_needed() | 如果元素不在视图中,滚动到可见位置 | |
query_selector(selector) | 在元素内查找子元素,返回第一个匹配的元素句柄 | selector |
query_selector_all(selector) | 在元素内查找子元素,返回所有匹配的元素句柄 | selector |
判断类
| 方法 | 作用 | 参数 |
|---|---|---|
is_checked() | 判断复选框或单选按钮是否被选中 | |
is_disabled() | 判断元素是否被禁用 | |
is_enabled() | 判断元素是否可用 | |
is_editable() | 判断元素是否可编辑常用于表单 | |
is_hidden() | 判断元素是否隐藏 | |
is_visible() | 判断元素是否可见 |
文件操作
文件上传
file = {
"name": "example.txt", # 文件名
"mimeType": "text/plain", # 文件类型
"buffer": b"Hello, Playwright!" # 文件内容,二进制
}
upload_input = page.locator('input[type="file"]')
upload_input.set_input_files(files=[file])
# 使用 open 方式上传本地文件
upload_input.set_input_files(files=[{
"name": "local_file.txt",
"mimeType": "text/plain",
"buffer": open("path/to/local_file.txt", "rb").read()
}])按键操作 (不常用)
| 方法 | 作用 | 参数 |
|---|---|---|
keyboard.down(key) | 按下按键 | key |
keyboard.up(key) | 松开按键 | key |
keyboard.press(key, delay) | 按下并松开按键 | keydelay=0 |
keyboard.type(text, delay) | 输入文本 | textdelay=0 |
支持按键如下,如果多个一起使用,可以 page.keyboard.down('Shift+A')
F1-F12 0-9 a-z A-Z Backspace Delete End Enter Escape Home Insert PageDown PageUp Tab ArrowDown ArrowLeft ArrowRight ArrowUp Control Alt Shift Meta...鼠标操作 (不常用)
| 方法 | 作用 | 参数 |
|---|---|---|
mouse.click() | 点击指定位置 | x, ybutton='left'/'right'/''middle'click_count=1delay=0 |
mouse.dblclick(x, y, button, delay) | 双击指定位置 | x, ybutton='left'/'right'/''middle'delay=0 |
mouse.down(button, click_count) | 按下鼠标按钮 | button='left'/'right'/'middle'click_count=1 |
mouse.move(x, y, steps) | 移动鼠标到指定位置 | |
mouse.up(button, click_count) | 松开鼠标按钮 | button='left'/'right'/'middle'click_count=1 |
mouse.wheel(delta_x, delta_y) | 滚动鼠标滚轮 | delta_xdelta_y |
# 先移动到 (100, 100) 位置
page.mouse.move(100, 100)
# 点击左键
page.mouse.click(100, 100, button='left')
# 双击右键
page.mouse.dblclick(100, 100, button='right')
# 按下左键
page.mouse.down(button='left')
# 松开左键
page.mouse.up(button='left')
# 滚动鼠标滚轮
page.mouse.wheel(0, 100) # 向下滚动 100iframe 操作
# 找到并进入 iframe
frame = page.frame_locator('iframe')
frame.locator('#chat-textarea').fill('你好')
frame.locator('#chat-submit-button').click()
# 等待 5s 看结果
page.wait_for_timeout(5000)页面滚动
大多数情况下,会自动滚动到可见位置,但有时需要手动滚动。极少数情况下可能需要手动滚动比如无限滚动的列表。
# 如果需要滚动到某个元素
page.locator('selector').scroll_into_view_if_needed()
# 也可以通过 mouse 的 wheel 方法滚动
page.mouse.wheel(0, 1000) # 向下滚动 1000 像素
# 也可以通过 evaluate 方法执行 JavaScript 进行滚动
page.evaluate("window.scrollTo(0, document.body.scrollHeight)") # 滚动断言
定位器断言
文档断言则是 async_api 的另一个方法 expect,它可以对定位器进行断言。
正向断言
| 方法 | 作用 |
|---|---|
to_be_checked() | 断言复选框或单选按钮被选中 |
to_be_disabled() | 断言元素被禁用 |
to_be_editable() | 断言元素可编辑 |
to_be_empty() | 断言元素为空 |
to_be_enabled() | 断言元素可用 |
to_be_focused() | 断言元素获得焦点 |
to_be_in_viewport() | 元素与视口是否相交 |
to_be_hidden() | 断言元素不可见 |
to_be_visible() | 断言元素可见 |
to_contain_text(text) | 断言元素包含指定文本 |
to_contain_class(class_name) | 断言元素包含指定类名 |
to_have_attribute(name, value) | 断言元素具有指定属性和值 |
to_have_count(count) | 断言定位器匹配的元素数量 |
to_have_class(css_name) | 全量对比 class name 是否相等 |
to_have_id(id) | 断言元素具有指定 id |
to_have_text(text) | 断言元素的文本内容 |
page.locator('').to_be_checked()
page.locator('').to_be_disabled()
page.locator('').to_be_editable()
page.locator('').to_be_empty()
page.locator('').to_be_enabled()
page.locator('').to_be_focused()
page.locator('').to_be_in_viewport()
page.locator('').to_be_hidden()
page.locator('').to_be_visible()
# 是否包含指定文本
page.locator('').to_contain_text('text')
# 是否包含指定类名
page.locator('').to_contain_class('class_name')
# 是否具有指定属性和值
page.locator('').to_have_attribute('name', 'value')
# 定位器匹配的元素数量是否为1
page.locator('').to_have_count(1)
# 全量对比 class name 是否相等
page.locator('').to_have_class('css_name')
# 断言元素具有指定 id
page.locator('').to_have_id('id')
# 是否完全包含指定文本
page.locator('').to_have_text('text')反向断言
| 方法 | 作用 |
|---|---|
not_to_be_checked() | 断言复选框或单选按钮未被选中 |
not_to_be_disabled() | 断言元素未被禁用 |
not_to_be_editable() | 断言元素不可编辑 |
not_to_be_empty() | 断言元素不为空 |
not_to_be_enabled() | 断言元素不可用 |
not_to_be_focused() | 断言元素未获得焦点 |
not_to_be_in_viewport() | 元素与视口不相交 |
not_to_be_hidden() | 断言元素可见 |
not_to_be_visible() | 断言元素不可见 |
not_to_contain_text(text) | 断言元素不包含指定文本 |
not_to_contain_class(class_name) | 断言元素不包含指定类名 |
not_to_have_attribute(name, value) | 断言元素不具有指定属性和值 |
not_to_have_count(count) | 断言定位器匹配的元素数量不为指定值 |
not_to_have_class(css_name) | 全量对比 class name 不相等 |
not_to_have_id(id) | 断言元素不具有指定 id |
not_to_have_text(text) | 断言元素的文本内容不为指定值 |
页面断言
文档 针对 page 对象的断言
| 方法 | 作用 |
|---|---|
to_have_title(title) | 断言页面标题 |
to_have_url(url) | 断言页面 URL |
not_to_have_title(title) | 断言页面标题不为指定值 |
not_to_have_url(url) | 断言页面 URL 不为指定值 |
为什么不需要等待
playwright 具有自动等待功能,常见的操作如点击、输入等会自动等待元素可交互。等待的逻辑如下。
- 定位器解析为一个元素
- 元素可见
- 元素是稳定的 ,如非动画或已完成的动画
- 元素接收事件 ,不会被其他元素遮挡
- 元素已启用
包括断言也是会自动重试,直到条件满足才通过。以消除不确定性
Pytest 集成
推荐练习项目 Todo List,可以练习 playwright 的各种功能。
import pytest
from playwright.sync_api import expect, Page
# 每个测试函数前后执行
# scope: "function" 每个函数前后执行
# autouse=True 自动使用,会将 page 作为参数传入后续的测试函数
# 使用 pytest 时不用再调用 sync_playwright.start() 方法
@pytest.fixture(scope="function", autouse=True)
def test_before_or_after_each(page: Page):
print('before test...')
page.goto("http://127.0.0.1:5500/template/index.html")
yield
print('after test...')
def test_browser(page: Page):
# 浏览器是否拥有这个 title
expect(page).to_have_title("Playwright Document Title")
def test_checkbox_is_checked(page: Page):
checkbox = page.locator("input[type='checkbox']")
# 选中元素
checkbox.set_checked(True)
# 判定元素是否被选中
expect(checkbox).to_be_checked()
def test_submit_click(page: Page):
submit_btn = page.locator("button.submit")
submit_btn.click()
# 如果点击之后文本没有变更则截图
modified_text = 'Submitted'
if submit_btn.text_content() != modified_text:
page.screenshot(path="click-error.png")
# 点击之后判定元素文本是否变更
expect(submit_btn).to_have_text(modified_text)运行和调试
# 调试模式运行某个文件进行测试
PWDEBUG=1 uv run pytest -s test_playwright.py
# 直接运行会默认使用 chromium 无头模式,运行时不会打开窗口
uv run pytest
# 可以指定某些目录或文件,可以指定多个
uv run pytest tests/auto/ tests/auto/test_playwright.py
# -k 指定运行某个测试函数
uv run pytest -k test_browser
# --headed 有头模式下运行
uv run pytest --headed
# --browser 指定浏览器运行 可以是多个
uv run pytest --browser=chromium --browser=firefox
# --numprocess 进程数,建议一般的 cpu 核心数
uv run pytest --numprocess 4