setState 是异步还是同步?
在 React 得到元素树之后,React 会自动计算出新的树与老树的节 点差异,然后根据差异对界面进行最小化重渲染。在差异计算算法中, React 能够相对精确地知道哪些位置发生了改变以及应该如何改变, 这就保证了按需更新,而不是全部重新渲染。 如果在短时间内频繁 setState。React 会将 state 的改变压入栈中, 在合适的时机,批量更新 state 和视图,达到提高性能的效果
setState 并不是单纯同步/异步的,它的表现会因调用场景的不同而 不同。在源码中,通过 isBatchingUpdates 来判断 setState 是先 存进 state 队列还是直接更新,如果值为 true 则执行异步操作, 为 false 则直接更新
异步:在 React 可以控制的地方,就为 true,比如在 React 生命 周期事件和合成事件中,都会走合并操作,延迟更新的策略。
同步:在 React 无法控制的地方,比如原生事件,具体就是在 addEventListener 、setTimeout、setInterval 等事件中,就只能
调用 setState 之后发生了什么?
- 在
setState的时候,React 会为当前节点创建一个updateQueue的更新列队。 - 然后会触发
reconciliation过程,在这个过程中,会使用名为Fiber的调度算法,开始生成新的Fiber树,Fiber算法的最大特点是可以做到异步可中断的执行。 - 然后 React
Scheduler会根据优先级高低,先执行优先级高的节点,具体是执行doWork方法。 - 在
doWork方法中,React会执行一遍updateQueue中的方法,以获得新的节点。然后对比新旧节点,为老节点打上 更新、插入、替换 等 Tag。 - 当前节点
doWork完成后,会执行performUnitOfWork方法获得新节点,然后再重复上面的过程。 - 当所有节点都
doWork完成后,会触发commitRoot方法,React进入commit阶段。 - 在
commit阶段中,React会根据前面为各个节点打的 Tag,一次性更新整个dom元素。
受控组件和非受控组件区别是啥?
- 受控组件是 React 控制中的组件,并且是表单数据真实的唯一来源。
- 非受控组件是由 DOM 处理表单数据的地方,而不是在 React 组件中。
尽管非受控组件通常更易于实现,因为只需使用 refs 即可从 DOM 中获取值,但通常建议优先选择受控制的组件,而不是非受控制的组件。
这样做的主要原因是受控组件支持即时字段验证,允许有条件地禁用/启用按钮,强制输入格式。
聊聊 react@16.4 + 的生命周期
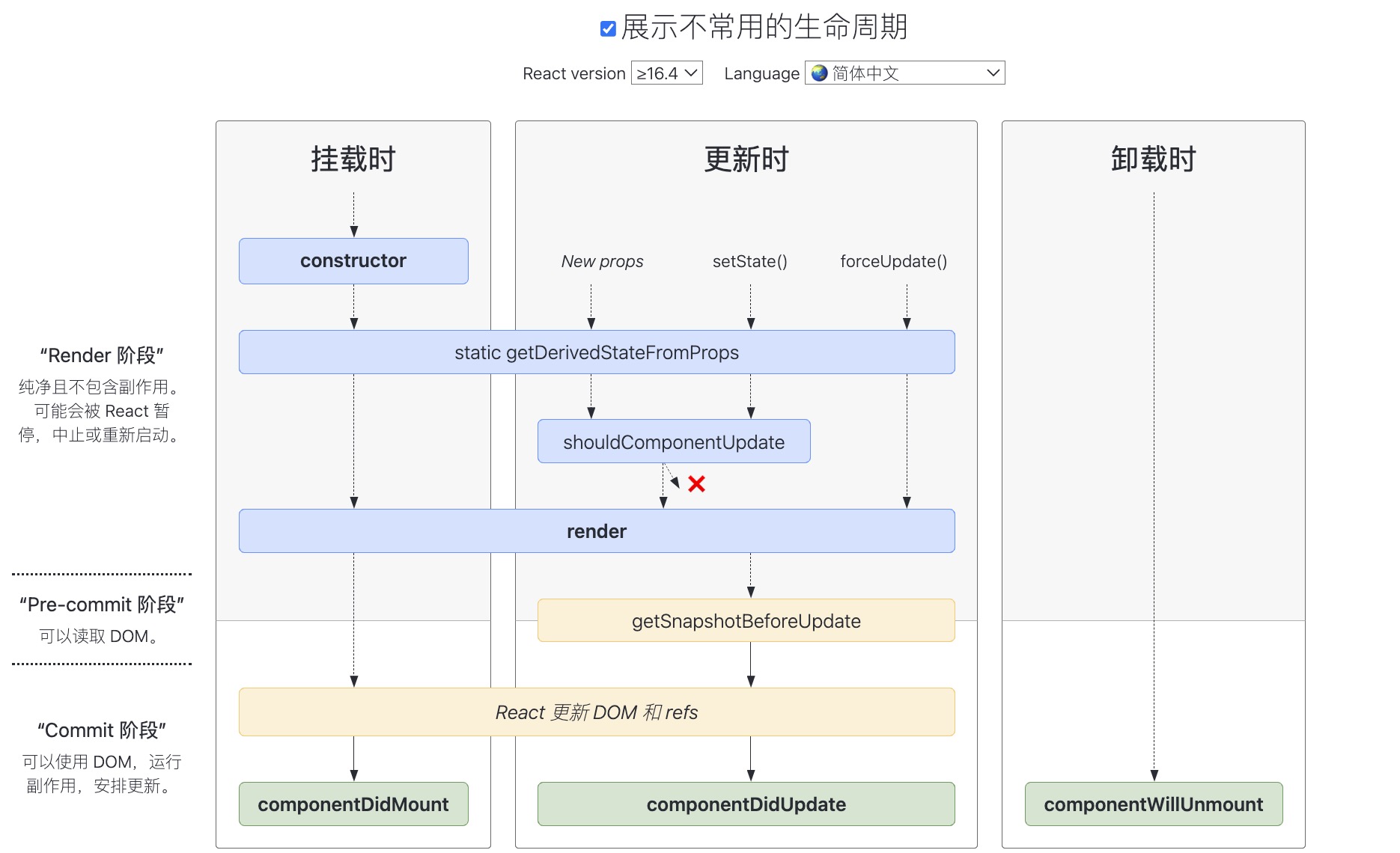
挂载过程: constructor -> getDerivedStateFromProps -> render -> componentDidMount
更新过程: getDerivedStateFromProps -> shouldComponentUpdate -> render -> getSnapshotBeforeUpdate -> componentDidUpdate
卸载过程: componentWillUnmountshouldComponentUpdate 返回 boolean 用于控制是否渲染组件。本身也会接收最新的 props 和 state
class Child extends React.Component {
state = { username: "zhangsan" };
shouldComponentUpdate(nextProps, nextState) {
// 通过判断 username 是否相同,返回 boolean 确认是否让组件重新 render
if (this.state.username === nextState.username) {
return false;
}
return true;
}
render() {
return (
<>
<div>{this.state.username}</div>
<button onClick={() => this.setState({ username: "lisi" })}>changeState</button>
</>
);
}
}getSnapshotBeforeUpdate 必须返回一个值不能为 undefined,返回值会作为 componentDidUpdate 的第三个参数,注意这个钩子必须和 componentDidUpdate 同时出现
class Child extends React.Component {
state = {
list: [1, 2, 3, 4, 5, 6, 7, 8, 9],
insertList: [11, 22, 33, 44, 55, 66, 77, 88, 99]
};
wraperRef = React.createRef();
getSnapshotBeforeUpdate(nextProps, nextState) {
// 返回更新之前的高度
return this.wraperRef.current.scrollHeight;
}
componentDidUpdate(prevProps, prevState, snapshot) {
// 获取更新后的高度
const scrollHeight = this.wraperRef.current.scrollHeight;
// 设置滚动条的高度
this.wraperRef.current.scrollTop += scrollHeight - snapshot;
}
render() {
return (
<>
{/* 假设需要点击之后需要让滚动条记住更新前的位置则可以使用 getSnapshotBeforeUpdate */}
<button onClick={() => this.setState({ list: [...this.state.insertList, ...this.state.list] })}>insert</button>
<div style={{ height: "200px", overflow: "auto" }} ref={this.wraperRef}>
{this.state.list.map(item =>
return (
<div key={item} style={{ lineHeight: "50px", backgroundColor: item % 2 === 0 ? "skyblue" : "hotpink" }}>
{item}
</div>
);
)}
</div>
</>
);
}
}getDerivedStateFromProps 是一个静态方法,该方法接收新的 props 和 老的 state 并返回一个对象。这个对象会合并组件的 state
class Child extends Component {
state = { username: "zhangsan" };
static getDerivedStateFromProps(nextProps, prevState) {
return {
age: 24
};
}
render() {
return (
<>
<button onClick={() => this.setState({})}>forceUpdate</button>
<div>{JSON.stringify(this.state)}</div>
</>
);
}
}useEffect(fn, []) 和 componentDidMount 有什么差异?
useEffect 会捕获 props 和 state。所以即便在回调函数里,你拿到的还是初始的 props 和 state。如果想得到“最新”的值,可以使用 ref。
hooks 为什么不能放在条件判断里?
以 setState 为例,在 react 内部,每个组件(Fiber)的 hooks 都是以链表的形式存在 memoizeState 属性中:
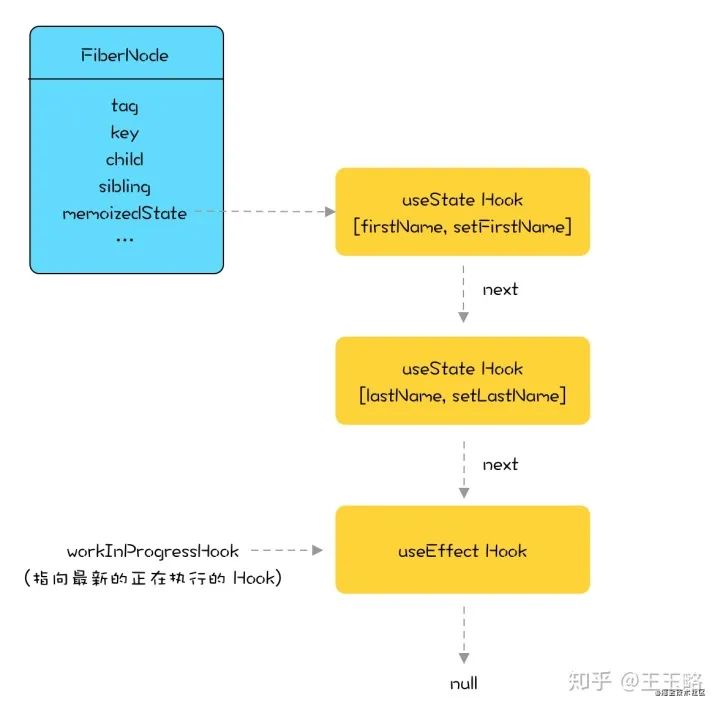
update 阶段,每次调用 setState,链表就会执行 next 向后移动一步。如果将 setState 写在条件判断中,假设条件判断不成立,没有执行里面的 setState 方法,会导致接下来所有的 setState 的取值出现偏移,从而导致异常发生。
总结: 因为 Hooks 的设计是基于链表实现。在调用时按顺序加入数组中,如果使用循环、 条件或嵌套函数很有可能导致数组取值错位,执行错误的 Hook。
fiber 是什么?
React Fiber 用类似 requestIdleCallback 的机制来做异步 diff。但是之前数据结构不支持这样的实现异步 diff,于是 React 实现了一个类似链表的数据结构,将原来的 递归 diff 变成了现在的 遍历 diff,这样就能做到异步可更新了
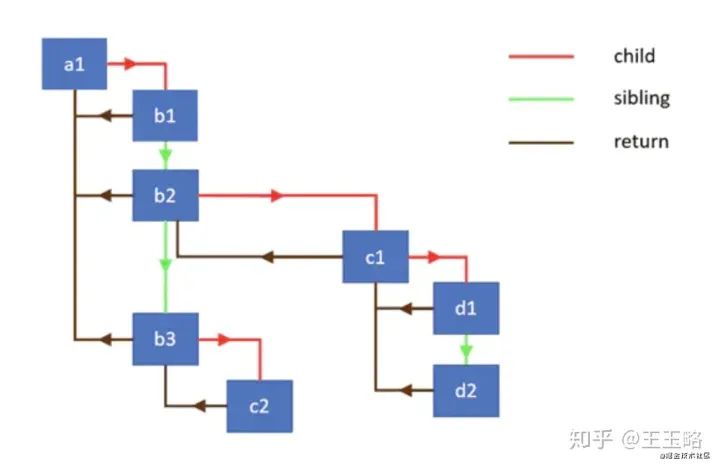
聊一聊 diff 算法
传统 diff 算法的时间复杂度是 O(n^3),这在前端 render 中是不可接受的。为了降低时间复杂度,react 的 diff 算法做了一些妥协,放弃了最优解,最终将时间复杂度降低到了 O(n)。
- tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动。如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
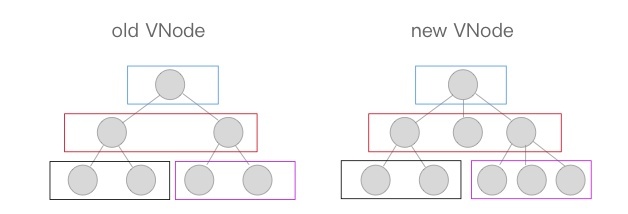
- component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
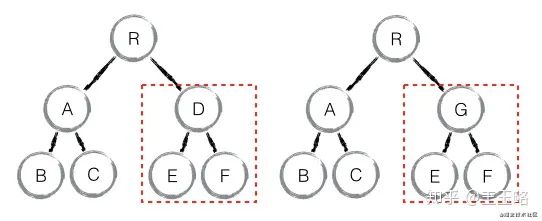
- element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分。如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染。这也是为什么渲染列表时为什么要使用唯一的 key。
为什么虚拟 dom 会提高性能?
虚拟 dom 相当于在 JS 和真实 dom 中间加了一个缓存,利用 diff 算法避免了没有必要的 dom 操作,从而提高性能。
错误边界是什么?它有什么用?
在 React 中,如果任何一个组件发生错误,它将破坏整个组件树,导致整页白屏。这时候我们可以用错误边界优雅地降级处理这些错误。
class ErrorBoundary extends React.Component<IProps, IState> {
constructor(props: IProps) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError() {
// 更新 state 使下一次渲染能够显示降级后的 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// 可以将错误日志上报给服务器
console.log("组件奔溃 Error", error);
console.log("组件奔溃 Info", errorInfo);
}
render() {
if (this.state.hasError) {
// 你可以自定义降级后的 UI 并渲染
return this.props.content;
}
return this.props.children;
}
}React 组件间有那些通信方式?
父组件向子组件通信: 通过 props 传递
子组件向父组件通信: 主动调用通过 props 传过来的方法,并将想要传递的信息,作为参数,传递到父组件的作用域中
跨层级通信: 使用 react 自带的 Context 进行通信,createContext 创建上下文, useContext 使用上下文。
使用 Redux 或者 Mobx 等状态管理库
使用订阅发布模式
React 父组件如何调用子组件中的方法?
如果是在方法组件中调用子组件(>= react@16.8),可以使用 useRef 和 useImperativeHandle
const { forwardRef, useRef, useImperativeHandle } = React;
const Child = forwardRef((props, ref) => {
useImperativeHandle(ref, () => ({
getAlert() {
alert("getAlert from Child");
}
}));
return <h1>Hi</h1>;
});
const Parent = () => {
const childRef = useRef();
return (
<div>
<Child ref={childRef} />
<button onClick={() => childRef.current.getAlert()}>Click</button>
</div>
);
};如果是在类组件中调用子组件(>= react@16.4),可以使用 createRef
class Parent extends Component {
constructor(props) {
super(props);
this.child = React.createRef();
}
onClick = () => {
this.child.current.getAlert();
};
render() {
return (
<div>
<Child ref={this.child} />
<button onClick={this.onClick}>Click</button>
</div>
);
}
}
class Child extends Component {
getAlert() {
alert("getAlert from Child");
}
render() {
return <h1>Hello</h1>;
}
}React 有哪些优化性能的手段?
类组件中的优化手段
- 使用纯组件 PureComponent 作为基类。
- 使用 React.memo 高阶函数包装组件。
- 使用 shouldComponentUpdate 生命周期函数来自定义渲染逻辑。
方法组件中的优化手段
- 使用 useMemo。
- 使用 useCallBack。
其他方式
- 在列表需要频繁变动时,使用唯一 id 作为 key,而不是数组下标。
- 必要时通过改变 CSS 样式隐藏显示组件,而不是通过条件判断显示隐藏组件。
- 使用 Suspense 和 lazy 进行懒加载
为什么 React 元素有一个 $$typeof 属性?
目的是为了防止 XSS 攻击。因为 Synbol 无法被序列化,所以 React 可以通过有没有 $$typeof 属性来断出当前的 element 对象是从数据库来的还是自己生成的。
如果没有 $$typeof 这个属性,react 会拒绝处理该元素。
React 如何区分 Class 组件 和 Function 组件?
一般的方式是借助 typeof 和 Function.prototype.toString 来判断当前是不是 class。但是这个方式有它的局限性,因为如果用了 babel 等转换工具,将 class 写法全部转为 function 写法,上面的判断就会失效。
function isClass(func) {
return typeof func === "function" && /^class\s/.test(Function.prototype.toString.call(func));
}React 区分 Class 组件 和 Function 组件的方式很巧妙,由于所有的类组件都要继承 React.Component,所以只要判断原型链上是否有 React.Component 就可以了:
AComponent.prototype instanceof React.Component;HTML 和 React 事件处理有什么区别?
- 在 HTML 中事件名必须小写,而在 React 中需要遵循驼峰写法
- 在 HTML 中可以返回 false 以阻止默认的行为,而在 React 中必须地明确地调用 preventDefault()
合成事件是 react 模拟原生 DOM 事件所有能力的一个事件对象,其 优点如下:
- 兼容所有浏览器,更好的跨平台; 将事件统一存放在一个数组,避免频繁的新增与删除(垃圾回收)。
- 方便 react 统一管理和事务机制。
- 事件的执行顺序为原生事件先执行,合成事件后执行,合成事件会冒 泡绑定到 document 上,所以尽量避免原生事件与合成事件混用,如果原生事件阻止冒泡,可能会导致合成事件不执行,因为需要冒泡到 document 上合成事件才会执行。
React 事件机制
React 并不是将 click 事件绑定到了 div 的真实 DOM 上,而是在 document 处监听了所有的事件,当事件发生并且冒泡到 document 处的时候,React 将事件内容封装并交由真正的处理函数运行。这样的方式不仅仅减少了内存的消耗,还能在组件挂在销毁时统一订阅和移除事件。
除此之外,冒泡到 document 上的事件也不是原生的浏览器事件,而是由 react 自己实现的合成事件(SyntheticEvent)。因此如果不想要是事件冒泡的话应该调用 event.preventDefault()方法,而不是调用 event.stopProppagation()方法。
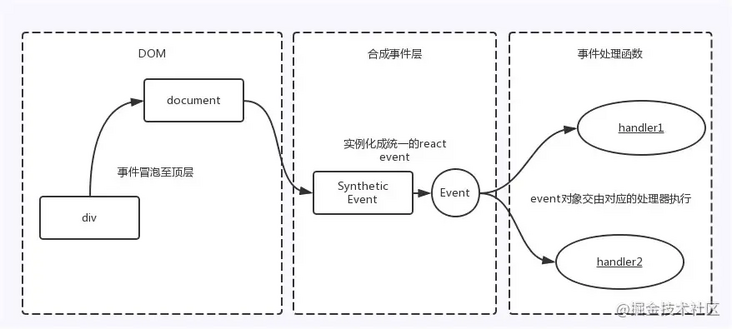
JSX 上写的事件并没有绑定在对应的真实 DOM 上,而是通过事件代理的方式,将所有的事件都统一绑定在了 document 上。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。
另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件(SyntheticEvent)。因此我们如果不想要事件冒泡的话,调用 event.stopPropagation 是无效的,而应该调用 event.preventDefault。
实现合成事件的目的如下:
- 合成事件首先抹平了浏览器之间的兼容问题,另外这是一个跨浏览器原生事件包装器,赋予了跨浏览器开发的能力;
- 对于原生浏览器事件来说,浏览器会给监听器创建一个事件对象。如果你有很多的事件监听,那么就需要分配很多的事件对象,造成高额的内存分配问题。但是对于合成事件来说,有一个事件池专门来管理它们的创建和销毁,当事件需要被使用时,就会从池子中复用对象,事件回调结束后,就会销毁事件对象上的属性,从而便于下次复用事件对象。
React 组件中怎么做事件代理?它的原理是什么?
React 基于 Virtual DOM 实现了一个 SyntheticEvent 层(合成事件 层),定义的事件处理器会接收到一个合成事件对象的实例,它符合 W3C 标准,且与原生的浏览器事件拥有同样的接口,支持冒泡机制, 所有的事件都自动绑定在最外层上。
在 React 底层,主要对合成事件做了两件事:
事件委派:React 会把所有的事件绑定到结构的最外层,使用统一的 事件监听器,这个事件监听器上维持了一个映射来保存所有组件内部 事件监听和处理函数。
自动绑定:React 组件中,每个方法的上下文都会指向该组件的实例, 即自动绑定 this 为当前组件。
React 高阶组件、Render props、hooks 有什么区别,为什么要不断迭代
这三者是目前 react 解决代码复用的主要方式:
- 高阶组件(HOC)是 React 中用于复用组件逻辑的一种高级技巧。HOC 自身不是 React API 的一部分,它是一种基于 React 的组合特性而形成的设计模式。具体而言,高阶组件是参数为组件,返回值为新组件的函数。
render props是指一种在 React 组件之间使用一个值为函数的 prop 共享代码的简单技术,更具体的说,render prop是一个用于告知组件需要渲染什么内容的函数 prop。- 通常,
render props和高阶组件只渲染一个子节点。让 Hook 来服务这个使用场景更加简单。这两种模式仍有用武之地,(例如,一个虚拟滚动条组件或许会有一个renderltem属性,或是一个可见的容器组件或许会有它自己的 DOM 结构)。但在大部分场景下,Hook 足够了,并且能够帮助减少嵌套。
React.Component 和 React.PureComponent 的区别
PureComponent 表示一个纯组件,可以用来优化 React 程序,减少 render 函数执行的次数,从而提高组件的性能。
在 React 中,当 prop 或者 state 发生变化时,可以通过在 shouldComponentUpdate 生命周期函数中执行 return false 来阻止页面的更新,从而减少不必要的 render 执行。React.PureComponent 会自动执行 shouldComponentUpdate。
不过,pureComponent 中的 shouldComponentUpdate() 进行的是浅比较,也就是说如果是引用数据类型的数据,只会比较不是同一个地址,而不会比较这个地址里面的数据是否一致。
redux 是什么?
Redux 是一个为 JavaScript 应用设计的,可预测的状态容器。
它解决了如下问题:
- 跨层级组件之间的数据传递变得很容易
- 所有对状态的改变都需要 dispatch,使得整个数据的改变可追踪,方便排查问题。
但是它也有缺点:
- 概念偏多,理解起来不容易
- 样板代码太多
为什么使用 jsx 的组件中没有看到使用 react 却需要引入 react?
本质上来说 JSX 是 React.createElement(component, props, ...children)方法的语法糖。在 React 17 之前,如果使用了 JSX,其实就是在使用 React, babel 会把组件转换 为 CreateElement 形式。在 React 17 之后,就不再需要引入,因 为 babel 已经可以帮我们自动引入 react。
react-router 里的 Link 标签和 a 标签的区别
从最终渲染的 DOM 来看,这两者都是链接,都是 a 标签,区别是 ∶ <Link>是 react-router 里实现路由跳转的链接,一般配合 <Route> 使用,react-router 接管了其默认的链接跳转行为,区别于传统的 页面跳转,<Link> 的“跳转”行为只会触发相匹配的<Route>对应的 页面内容更新,而不会刷新整个页面。