AI 专业名词的解释(搬运)
蒸馏 (Distillation)
NOTE
定义:将一个较大的复杂模型(教师模型)训练的知识迁移到一个较小的模型(学生模型)。
其实你如果了解了这玩意的操作流程你就能明白原理了。
一般来讲,我们先通过大量的数据来训练出一个大的模型。这个模型通常参数量很大,但是效率很低。
至于为什么效率很低,我的一种理解就是数据集的质量不够。互联网上直接拉下来的数据很多都比较“水”。所以,我们就可以让大的模型去生成一些数据,然后用这些数据去训练较小的模型。
很显然,小的模型的性能会很高,毕竟有效数据占的比例大多了。
例如大家可能发现了deepseek有时候会回答“我是GPT”,这可能就用GPT去生成数据来训练ds。这么训练可以节省很大的时间,方便快捷。
Token
NOTE
定义:文本中最小的语义单位。
我们用ai的时候经常会看到每百万 tokens 多少钱这种计费模式,但是 token 这玩意是啥呢? 如果不解释的太专业的话,你可以这么理解:
大模型在读一段文本的时候,会首先分词,也就是把文本给拆成一个一个的最小单位,这个单位就是1 token,然后大模型再进行处理。 例子:
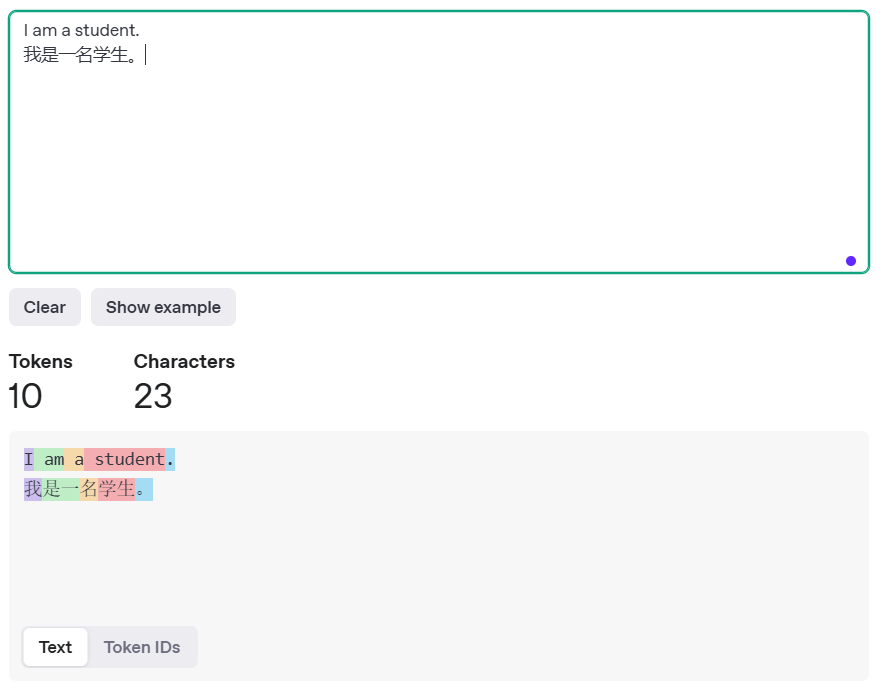
你应该也能理解到为什么是按token计费了。
多模态(Multimodal)
一个模型有着多模态,就意味着这个模型可以同时处理不同类型的数据,例如文本+图像+音频。
像 GPT-4o 就是一个明显的多模态模型,你可以让它识别出图片里的是啥。
但是,有一些模型,例如 deepseek r1,就没有多模态。比如说我在利用 deepseek r1做化学的时候,发现给它传键线式的化学物质表示它看不懂。后来我研究了以下,才发现 deepseek 官网的图片只能识别文字,用的就是比较简单的 OCR 技术。
现在大模型对着图像的识别还是有着一点问题的。这就是为什么一些人机验证咱能过去但是AI过不去的原因。
过拟合 (Overfitting)
![NOTE] 定义:模型在训练数据上表现良好,但在未见过的数据(测试集)上表现不佳。
这里有个通俗易懂的理解:学生党刷题都去刷一个类型的题了,然后考试考了个新题型就全寄了。也就是说,模型只是学会了给它训练的数据里的问题,但是没有扩展的能力。在训练的过程中,我们必须避免过拟合的发生,毕竟AI很多时候是拿来解决现实生活中的问题的。
这也是人类很多情况下比 AI 强的原因。人类可以在复杂多变的环境中有着很好的反应能力,但是 AI 想要拥有这个还是比较难的。
强化学习(RL)
这个名词大家可能在 Deepseek R1 的技术文档里看到多次。这其实很好理解。强化学习的核心我们可以理解为“试错”,通俗一点讲,也就是大模型在训练的过程中,如果它表现好了就给奖励,表现不好就来一嘴巴子,显然这么学习就会让AI很快地学会一种东西,并且效果良好。
想想你小时候犯了错挨揍是不是有效吧。
预训练(Pre-training)
NOTE
定义:在特定任务之前,通过大规模数据集训练模型,使其能够学习到通用的特征。
其实这个很好理解,在预训练阶段使用大量的未经审查的数据,从而让大模型对于所有的知识都有着一定的理解,让模型“全知全能”。如果全部数据都是人工合成筛选的,有没有可能出现遗漏的情况?况且也没有那么多人去干这个事情。
后训练(Post-training)
NOTE
定义:在预训练模型的基础上,进一步进行训练,使模型在特定任务上获得更好的表现。
这个也很好理解。假设说我们要训练一个生成代码的模型,我们就需要用大量这方面的数据集去让模型学会这个能力。后训练通常会使用大量的人工合成的数据来保证训练的高效。
训练损失(Training Loss)
训练损失是模型在训练过程中用来衡量预测与实际结果之间差距的一个指标。这个一般是在训练/微调的过程当中用于监测的。通常来讲,测量的是模型在回答数据集中的问题时候的准确性。
训练损失通常在训练过程中不断下降。
微调(Fine-tuning)
这玩意在后训练里面用的挺多的。
通过在较小的标注数据集上继续训练预训练好的模型,目的是让它适应特定任务。
通常来讲,微调所采用的数据集量远远小于在预训练中采用的数据集量。你可以这么理解:微调是为了让模型在解决任务的时候知道该往哪个方向去想,应该去如何回答用户,从而避免乱想影响准确性和效率。